 jmettraux.skepti.ch
jmettraux.skepti.ch
20190422 rufus-scheduler 3.6.0 released
The last Ruby Weekly contained a pointer to Resque-Scheduler in its "Code & Tools" section. I was a bit intrigued, it's been years since Ruby Weekly reposted anything I pushed to RubyFlow about rufus-scheduler (or its dependencies like fugit.
Resque-Scheduler was the first project to combine Resque and rufus-scheduler. When Sidekiq rose, sideqik-scheduler and sideqik-cron appeared.
I was happy to see the embargo somehow worked around and a project using some of my work being showcased.
I haven't had a look at Resque-Scheduler in ages. I looked at the issues and found one quite recent that could be addressed by me, as a dependency provider.
It has two parts:
- Invalid cron strings were failing at schedule time as expected, but the message was not helping at all, fugit#19
- Somehow older versions of rufus-scheduler were accepting
"/15 * * * *"but newer versions, based on fugit do not, rufus-scheduler#289
I fixed both issues and released rufus-scheduler 3.6.0 and fugit 1.2.0.
I used to say "build it and they will complain", but sometimes, you have to dig to find the those complaints.
update: I forgot to mention Que-Scheduler which combines Que and fugit. Thanks again to Harry, its author, for his contributions to fugit.
20190416 reddit answer on workflow engines
Here is an answer I wrote for go to resource on how to build a workflow engine.
Robert was asking:
So I'm researching how to build a workflow engine, is there like a "standard work" or "go to resource" for this topic? Just starting out, will keep a log here.
That makes for a cheap blog post, but I'd like to keep that as an archive.
my answer
I built three workflow engines over the years. I have never found a "how to build a workflow engine" resource, but I found workflow engines (all of them proprietary when I started), research papers about workflow modelling, budding industry standards, and blogs.
My idea of a workflow engine, then and now, was of a tool that accepts a model of a business process (a workflow definition), something rather high-level describing the flow of work among participants to produce a business result. The developers and the business people should be able to gather around such a document and agree on it (later on, iterate on it to adapt to new situations).
The document/model/piece of code should rally business logic, instead of having it scattered all over the place.
For the two last engines I built, I used the Workflow Patterns to guide me, more specifically, the Control-Flow Patterns. A workflow engine, in my opinion, has to cover the principal patterns listed there to be of any use.
Another resource I came to appreciate, is BPMN. It's a business process model and notation. It is mostly used to document business processes and a subset of it is destined for "execution". I have seen organizations use BPMN to document "manual" business processes "as is", and sometimes to model business processes for execution by a workflow engine "to be".
BPMN is important because more business people are getting exposed to it. They are attracted like flies to the promise of drawing executable diagrams. Ten years ago, the buzzword was "no code". But then, recently, it became "low code". It's hard to abstract away the programming.
My favourite blog about BPMN and its surroundings is Process Is The Main Thing.
It might be necessary to look the series of blog posts culminating in Business Process Models are Not Agile for a rebuttal of the grail of business process modelling.
It seems that many times, a box and arrow system is too top-down to succeed. It'd be better to have a kind of task list with termination and delegation rules/constraints, and tracing. The balance is yours to find.
A task / worklist system at the front, with a workflow engine behind driving some of the non-loose business processes might make a good combination. When building task lists I tend to look at Workflow Resource Patterns, the resource subset of the patterns mentioned above.
You could start with a tasklist and as the time passes, iterate towards having the repetitive task patterns codified into business processes, cataloged in a process portfolio, itself iterating as the business conditions evolve.
You will also come across the term "workflow engine", but that'll cover scientific workflow engines as well, those are more specialized into the process of data workflows. From the other answers here, I guess you are more interested into "business process" engines. Googling for "Ruby workflow" will lead you in world of development techniques.
So, the resources I have found and used are mostly about what to build, not how to build it. As a programmer, my customers usually tell me what to build and the how to is for me to figure.
My two Ruby workflow engines are ruote which is now dead, and its successor flor. They are web framework agnostic. For the task/worklist companion to flor, I am building florist.
In the flor readme, you'll find a list of other Ruby (and Rails) workflow engines.
20190407 flor workflow engine
flor is a workflow engine. It's written in Ruby.
A workflow engine is a host for workflow executions, business processes that might last from a few minutes to multiple years.
Such an engine takes as input workflow definitions and an initial set of data and controls the execution "flow" until success or failure.
tl&dr
Look at flor's readme, at its one Ruby file doc/quickstart0, or at its more frameworky complex doc/quickstart1.
workflow definitions
At its core, flor is an interpreter for the flor workflow language. The "work" in "workflow" is assumed by taskers. Flor and its language deal with the control flow between taskers.
Flor doesn't use a Ruby DSL or a BPMN diagram to represent its workflows. The flor language is a programming language dedicated to workflows. It has its advantages and disadvantages, as with all pieces of software, we shall hopefully iterate towards a language that covers a large part of its community needs.
Here is an example reporting workflow, it involves five human participants and two automated taskers:
alice 'prepare feedback forms'
concurrence
eric 'gather customer feedback' timeout: '8d'
fred 'gather customer feedback' timeout: '8d'
greg 'gather customer feedback' timeout: '8d'
anonymize_feedback _
loop
alice 'prepare report'
brent 'validate report'
break _ if f.valid
submit_report _
brent 'close report'
This example of workflow definition routes work from Alice, fans out to Eric, Fred, and Greg, giving them each 8 days to gather customer feedback. Once all have replied (or 8 days have elapsed), the feedback is anonymized. A back and forth between Alice and Brent is started, until Brent deems the report ready for submission (by setting the field valid to true). Finally Brent closes the report.
The flow definition weaves in calls to taskers, moving tasks from one to the next.
Any number of workflow executions can coexist in a flor instance. A workflow execution in a given version can coexist with a workflow execution following the same definition or any other definition. Executions following the same definition but in different versions can coexist.
taskers
A tasker is a piece of Ruby code that is called to perform a task. Here is the code behing the anonymize_feedback _ above:
class Acme::AnonymizeFeedbackTasker < Flor::BasicTasker
def task
Acme::Models::Forms #
.where(exid: exid) #
.each(&:anonymize) # access DB (Sequel style) and anonymize each
.each(&:save) # form related to this execution (exid)
reply # hand back task to flor
end
end
The flor language and the taskers try to be orthogonal. Taskers should be easy to test on their own and be usable from multiple workflow definitions.
When flor is set up with a HashLoader, it's fairly easy to directly bind tasker implementations to the names appearing in the workflow definition:
FLOR = Flor::Unit.new(
loader: Flor::HashLoader,
sto_uri: 'postgres://flor:xxx@localhost/flor')
%w[ alice eric fred greg brent ].each do |user|
FLOR.add_tasker(user, Acme::HumanTasker)
end
FLOR.add_tasker(:anonymize_feedback, Acme::AnonymizeFeedbackTasker)
FLOR.add_tasker(:submit_report, Acme::SubmitReportTasker)
Human taskers are usually placing the incoming task into a worklist, let users edit it and then, when they're done with it, return the task to flor. There is the florist project providing a vanilla flor worklist, but it's work in progress.
launching
In the case of a web application, the launch of a new workflow execution usually happens in a controller, here is an example Sinatra POST endpoint:
post '/xhr/reports/' do
exid = FLOR.launch(
REPORT_FLOW,
payload: prepare_payload(request))
content_type 'application/json'
{ exid: exid }.to_json
end
Behind the scene, that simply puts a launch message in flor's database and returns quickly the exid for the new workflow execution.
two kinds of configuration
More advanced flor deployments might favour the configuration tree approach demonstrated in flor/quickstart1/. Taskers and flows are placed in a tree hierarchy mimicking an organization's domain and subdomains. (What stands behind a subflow or a tasker might thus depend in which (sub-)domain the flow is launched).
The example in this post is based on the straightforward flor/quickstart0/ which spans a simple Ruby file.
two kinds of setup
The simplest way to deploy flor is within the web application it serves, in the same Ruby process. That's what I use in production, thanks to the wonderful JRuby.
A more classical setup is to have 1 or more Ruby processes dedicated to the web application and 1 or more Ruby processes for flor, a worker process. That's totally fine. The flor unit in the web processes can be instantiated without being started, while the flor unit in the worker processes is started. The flor units share the same database and communicate via it. (See doc/multi_instance.md).
flor characteristics
- Written in Ruby
- Not tied to any (web) framework
- Only one major dependency, the excellent Sequel
Ruby might be deemed a slow language, but it's fast enough when thinking of business processes spanning long periods of times.
flor features
- Has support for timeouts and time scheduling
- Workflows can be cancelled completely or in part
- Workflows can be re-applied with newer versions of part of their definition
- Errors handlers can be set at various levels
- Workflows can wait for signals
- etc
over
If you have any question, please ask in the flor Gitter room or via the GitHub issues.
20180927 the flor language
Flor is a language for defining workflows for the flor workflow engine.
A flor engine is an interpreter for the flor language. Usually an interpreter lives in an OS process and interprets a single program. With a flor engine, there are multiple program instances, called workflow executions, being interpreted in the same engine. Flor can host multiple executions of the same workflow definition or executions of various, different, workflow definitions. They could be various versions of the same workflow definition, or even executions whose definitions diverged in-flight from their original definition (rewriting the program in-flight).
Executions route work between taskers. Taskers are orthogonal to workflow definitions/executions. Multiple definitions/executions share the same set of taskers. For example the "accounting department" tasker or the "send notification email" tasker may appear in multiple workflow definitions (in the same business domain usually).
Executions spend most of their time waiting for taskers' answers, especially if those taskers are human.
This meandering post tries to show what flor, the language, looks like, and to explain the motivations behind that. This post doesn't look at tasker implementation, it is sufficient to know that they are scripts (Ruby or not) accepting task messages and replying with an updated task payload or rejecting the task.
the language itself
Here is a sample flor workflow definition:
sequence
set item_id # the launch data is used
create_mandate _ # to create a new mandate
cursor
ops 'assign container number' # operations team
update_mandate status: f.status # ops decides on status
break _ if f.status == 'numbered' # break out of cursor if 'numbered'
rm 'rework mandate' # relationship manager
update_mandate status: 'agreed' # refines mandate data
continue _ # mandate goes back to operations...
pfs 'activate mandate' # portfolio team
update_mandate status: 'active' # activates the mandate
email 'rm' 'awm mandate activated' # success, email sent to rel manager
A few observations:
- It is indented
- There are no end of indentation levels, a leftward indentation change ends one or more indentation blocks, a rightward indentation change starts a new indentation block, it's like Python
- Lines begin with a word followed by arguments
- Arguments are strings or key: value entries, or sometimes
_ - Comments start with a
#sign and end with the end of their line - The head of line word sometimes is an imperative (set, break, update_mandate, email, ...), sometimes a noun (sequence, rm, ...)
- Like in Ruby, some lines end in a condition, for example:
break _ if f.status == 'numbered'
A few answers:
Each non-comment line is a "call" of the head-of-line word procedure
Some of those heads are common flor procedures (set, sequence, cursor, break, continue, ...)
Some of those heads are taskers (pieces of code registered in the flor engine and available to multiple flor definitions), here, for example, "rm", "ops" and "pfs" point to three distinct group in the organization using the flor engine, they are "human taskers"
Some of those heads are taskers pointing to non-human taskers, like "email" and "update_mandate", such taskers tend to perform their task immediately, while human taskers are usually delivering the task to a queue/list system where humans may pick them (and drop them back eventually)
Some of those heads could be functions (sorry, no function calls in the example above).
The suffix conditionals are in fact syntactic sugar:
break _ if f.status == 'numbered'
#
# gets rewritten to:
#
if
f.status == 'numbered' # conditional
break _ # then branch
# nada... # else branch
Such rewrites occur when the flow reaches the break/if, not before.
The _ (underscore) as a single argument is necessary to distinguish getting the value of a head from calling it.
Consider:
define get-name
"Hector"
get-name # yields a pointer to the "get-name" function
get-name _ # yields "Hector"
Yielding a pointer to a function has its uses, for example, when aliasing it:
define add x y \ + x y
set plus add # alias plus to add
plus 1 2 # yields 3
set plus # set plus
add 2 3 # to the value of `(add 2 3)`, yields 5
plus 3 4 # yields 5, not 7
I'm sure there are more questions, feel free to open a question/issue on the flor issue tracker or to drop in for a chat in the flor chat room.
why such a language?
Like all programming languages, flor sits between the user and the interpreter. It has to be understood by the interpreter (fairly easy) and by the user (difficult) and his co-workers (even more difficult).
Business people out there know and use BPMN. Why not use that?
Please note that I describe flor as a "workflow engine", not a "business process management suite". I am not really targetting business users, I am targetting fellow developers. Funnily, for most developpers, a workflow is in the realm of "my workflow", the set of ways in which they weave their work, all alone. Granted sometimes, there are team workflows, but there are much more blog posts about "my development workflow" out there than about team workflows.
Still, why not use BPMN? I prefer a text programming language to a visual programming language. I could go christian and say "In the beginning was the word", not the diagram. I also do not think that a diagram is not a program, there is no "no code", a workflow definition, text or diagram, is a piece of code. Most diagrams out there are backed by textual notations, we're back to word, text.
The basic blocks in a programming language come most of the time straight out of the English language: GOTO, if, car, cdr, RETF, whatever... We strive to have programs reading like English. If I target developers, I have not to forget that they'll be sharing those programs, those workflow definitions, with business users. It'd better be readable.
As already written, the flor language essentially routes work among taskers. Concise definitions should be readable. Throwing the work over the wall to a tasker should hide/abstract most of the complexity, then flor allows for functions, a classical way to abstract details away, flor then routes work among taskers and functions. The way a tasker is called is similar to the way a function is called: tasker name or function name, followed by arguments.
define phase1
concurrence
alice 'call A-N customers'
bob 'call M-Z customers'
define phase2
sequence
alice 'get customer confirmation'
bob 'do something else'
sequence
phase1 _ # function call
phase2 _ # function call
charly 'final phase' # tasker invocation
#verb_or_noun arguments*
# verb_or_noun arguments*
I am not against diagrams, I think they are great to provide the coup d'oeil that business users want. My language should lend itself to (semi-)automatic generation of diagrams. If "technical details" are hidden behind abstractions, meaningful diagram generation should be possible.
Ruote, the predecessor to flor had a Javascript library for diagram generation. Flor should have one too.
It still takes discipline to write readable flow definitions or to write graspable BPMN diagrams.
a Lisp bastard
Flor is a Lisp bastard, one of those that lost the parentheses. A word on its own is replaced by the value it stands for. A word is followed by arguments and we have a function call or a tasker invocation, or simply a procedure call.
The 10th Greenspun rule needn't apply, I am deliberately bringing a Lisp to the table. Granted, "bug-ridden", "slow" and "half-complete" may still hold.
If Lisp is the mother, who's the father? Ruby for sure.
# Lispish
#
map [ 1, 2, 3 ] #
def elt #
+ elt 3 # "map" accepts a function
# Rubyish
#
collect [ 1, 2, 3 ] #
+ elt 3 # while "collect" is a macro rewriting to a "map"
# both yield [ 4, 5, 6 ]
Surely, using flor to add 3 to a sequence of integers is a waste. Here is maybe a better example:
define notify_warranty_void users
#
set emails #
users #
collect #
elt.email # collect the email for each user into "emails"
notify emails "warranty void" # call to function "notify"
#
# OR
#
notify (users | collect \ elt.email) "warranty void" # as a one-liner
There is a list of the flor procedures, sorry, it doesn't contain "car" or "cdr" for the time being.
Why a Lisp bastard for defining workflows? I could answer that it's because I got taught about programming with the Wizard Book, but it's rather my wish for a language close to its symbolic expressions. I want this (verb_or_noun arguments*) structure.
conclusion
It can be said that I have an obsession for workflow engines, maybe it's more of a quest for a workflow language.
Lots of business processes are weaving among participants and services. Some of them are described (as-is BPMN diagrams), lots of them are bizlore.
Some business processes are backed by state machines, but most of the time, those are lifecycle business processes, they concern 1 entity, there might be a higher level business process driving the lifecycle of multiple entities.
Some business processes can be executed advantageously by a workflow engine. Having a workflow definition mapping one-to-one to a workflow execution is great. The definition can be versioned, executions of one or more versions of the same definition may coexist.
A portfolio of concise business processes / workflow definitions is very important. It takes discipline.
I am trying to provide a fun language to build that with.
20180626 L'Effroyable Tragédie

It's a book in french, I'll anyway write about it in english.
Here are a few things I take from the book:
As Napoleon was a warning for Hitler, Napoleon had the Charles XII warning.
The Berezina crossing featured a diversion at Baryssaw, but the troops crossed at Stoudianka.
The Russian army too suffered heavily from the winter cold, especially as they stretched westward.
20180604 Before the Dawn

After reading Guns, Germs, and Steel, I had to read Before the Dawn.
I liked it a lot. It was an easier read than Guns, Germs, and Steel. They feel complementary to me.
Each chapter of this book begins with a Charles Darwin The Descent of Man quote, it makes me want to read this particular book even more, but I have to admit that I am tempted by Tristram Shandy these days. Or should I re-read The Red Queen?
20180601 Gemfile.lock
If you are responsible for an application, a last-mile application, not a library (a gem), please check in your Gemfile.lock.
I recently released rufus-scheduler 3.5.0 and it was quiet, a few new stars, no comments on RubyFlow. Ruby Weekly did not pick up the release in its announcement, so I thought I was free to focus on other things.
A couple of days later, I got notified on GitHub, people were posting on an old, closed, sidekiq-cron issue:

Great, if the API had changed, I would have been glad to release as 4.0.0 instead of 3.5.0, but since sidekiq-cron currently depends on rufus-scheduler >= 3.3.0, sidekiq-cron would still be "not scheduling".
The problem was again reported in two more issues, #199 and #201, it also just found its way on Stack Overflow.
How is the concern voiced?
I have been using sidekiq-cron successfully over the past few months, now it stopped working overnight. #201
and
Suddenly all of our cron jobs were not being enqueued anymore #199
OK, so suddenly it stopped working? You didn't check in your Gemfile.lock, that's what you're exposing yourself to.
It saddens me to see that everybody jumps at the "let's depend on rufus-scheduler 3.4 in our Gemfile" pseudo-solution. It might be necessary for new integrations of sideqik-cron, but for "running" deploys, it's poor practice.
If you are responsible for an application, a last-mile application, not a library/gem, please check in your Gemfile.lock, it is meant to protect you from that kind of problems.
Updating your dependency gem versions is something you do deliberately, with your back covered by your test suite.
(please note that I submitted a pull request to sidekiq-cron to rework the sidekiq-cron to rufus-scheduler dependency)
20180515 rufus-scheduler 3.5.0 released
rufus-scheduler 3.5.0 just got released.
Rufus-scheduler is a job scheduling (at, in, every, cron) library available as a Ruby gem. It is not meant as a cron replacement, it lives within the Ruby process using it and dies with it.
require 'rufus-scheduler'
scheduler = Rufus::Scheduler.new
# ...
scheduler.in '10d' do
# do something in 10 days
end
scheduler.at '2030/12/12 23:30:00' do
# do something at a given point in time
end
scheduler.at '2030/12/12 23:30:00 Europe/Rome' do
# do something at a given point in time (Rome time zone)
end
scheduler.every '3h' do
# do something every 3 hours
end
scheduler.cron '5 0 * * *' do
# do something every day, five minutes after midnight
# (see "man 5 crontab" in your terminal)
end
scheduler.cron '5 0 * * * America/Los_Angeles' do
# same as above, but in the Los Angeles time zone
end
Rufus-scheduler lives in its own thread, keep that in mind when using it on a forking application server.
If you're looking for something that leverages the cron daemon, look at the excellent Whenever.
This 3.5.0 uses fugit for parsing time strings thrown at it. Fugit is the extraction of the time parsing/representing component of rufus-scheduler in its own gem.
Time.now #=> 2018-05-15 08:47:27 +0900
require 'fugit'
Fugit.parse('0 0 1 jan *').class # => Fugit::Cron
Fugit.parse('0 0 1 jan *').next_time.to_s # => "2019-01-01 00:00:00 +0900"
Fugit.parse('0 0 1 jan *').previous_time.to_s # => "2018-01-01 00:00:00 +0900"
Fugit.parse('12y12M').class # => Fugit::Duration
Fugit.parse('12y12M').to_sec # => 409536000
Fugit.parse('12y12M').to_iso_s # => "P12Y12M"
Fugit.parse('2017-12-12').class # => EtOrbi::EoTime
Fugit.parse('2017-12-12').to_s # => "2017-12-12 00:00:00 +0900"
Fugit.parse('2017-12-12 UTC').class # => EtOrbi::EoTime
Fugit.parse('2017-12-12 UTC').to_s # => "2017-12-12 00:00:00 Z"
Fugit.parse('every day at noon').next_time.to_s # => "2018-05-15 12:00:00 +0900"
Fugit.parse('every day at noon').previous_time.to_s # => "2018-05-14 12:00:00 +0900"
I need a separate time parsing library for flor so I extracted fugit out of rufus-scheduler.
Fugit uses raabro to parse strings, flor uses it as well but for parsing process definitions.
If you encounter issues with this new version of rufus-scheduler, please report at https://github.com/jmettraux/rufus-scheduler/issues.
Out.
20180509 Guns, Germs, and Steel

Up until now, I used to post the cover of the books I completed on Instagram.
From now on, I will post them here, in this classical blog. A friend told me I was an ass for posting book covers on Instagram, potentially making friends and family (almost 100% of my Instagram followers) angry at my prententiousness.
OK, so that was a fun ride. I'll post here instead. Almost nobody reads this blog, so I'm safe and I can focus on my book timeline goal. What did I read, when and what quote I could snapshot out of it.
Guns, and Roses
East-West, North-South, geographical partitions. I had to read it.
In the reading list, this book points at The Descent of Man and Before the Dawn.
20180327 fugit 1.1.0 released
I'm working on a newer version of Rufus-Scheduler, it'll probably be a 3.5.x.
Two important things behind rufus-scheduler are Time instances with time zones, this is provided by et-orbi and the parsing of time strings which is provided by fugit.
require 'fugit'
Fugit.parse('0 0 1 jan *').class # ==> ::Fugit::Cron
Fugit.parse('12y12M').class # ==> ::Fugit::Duration
Fugit.parse('2017-12-12').class # ==> ::EtOrbi::EoTime
Fugit.parse('2017-12-12 UTC').class # ==> ::EtOrbi::EoTime
Fugit.parse('every day at noon').class # ==> ::Fugit::Cron
Fugit understands cron strings, duration strings, and points in time. They are parsed to instances of, respectively, Fugit::Cron, Fugit::Duration, and EtOrbi::EoTime (the Time instance provided by et-orbi).
The fugit cron class provides methods for determining next or previous time and if a point in time matches.
require 'fugit'
c = Fugit::Cron.parse('0 0 * * sun')
# or
c = Fugit::Cron.new('0 0 * * sun')
p Time.now # => 2017-01-03 09:53:27 +0900
p c.next_time # => 2017-01-08 00:00:00 +0900
p c.previous_time # => 2017-01-01 00:00:00 +0900
p c.match?(Time.parse('2017-08-06')) # => true
p c.match?(Time.parse('2017-08-07')) # => false
p c.match?('2017-08-06') # => true
p c.match?('2017-08-06 12:00') # => false
Fugit understands the standard cron format (5 entries) and also an extended format with seconds (6 entries).
The release of this 1.1.0 is a motivated by a request from the authors of que-scheduler to support cron strings with timezones.
I was busy on other (floraison) things and I had forgotten to work on cron strings with timezones. They are necessary, since rufus-scheduler understands them. Fugit has to master them to become the basis of future rufus-scheduler releases.
20171021 flor design 0
I was approached on Twitter by Benjamin Dauvergne asking me about flor's design.
@jmettraux est-ce qu'on pourra avoir un jour un article de blog sur le design de ruote/flor ? :) Je n'ai jamais rien vu d'équivalent.
— Benjamin Dauvergne (@b_dauvergne) October 5, 2017
Could we have one day a blog post on the design of ruote/flor? :) I never saw anything equivalent.
Flor is a Ruby workflow engine. It is a new iteration of ruote which is now dead.
Ou des pointeurs sur l'inspiration, j'ai toujours du mal avec l'exécuteur d'expressions/message, on dirait un design tuplespace/whiteboard.
— Benjamin Dauvergne (@b_dauvergne) October 5, 2017
Or pointers on the inspiration, I always had troubles with the expressions/message executor, it looks like a tuplespace/whiteboard design.
(An entry point on tuple spaces: https://en.wikipedia.org/wiki/Tuple_space)
I pointed at flor's nascent documentation, but, well, that isn't a blog post, it's an index, not a gate.
Vu, mais j'ai toujours du mal avec les exécutions, les noeuds et les messages. Il faudrait un exemple concret du début à la fin.
— Benjamin Dauvergne (@b_dauvergne) October 16, 2017
Seen, but I still have trouble with the executions, the nodes and the messages. A concrete example, going from start to finish, would help.
Tel exécution lance tel message, tel fichier JSON est posé, etc.. :) Désolé si j'abuse un peu, mais ça parait assez magique.
— Benjamin Dauvergne (@b_dauvergne) October 16, 2017
This execution emits that message, this JSON file is produced, etc... :) Sorry if I push too far, but that looks quite magical.
ruote or flor
Flor builds on ruote. I only want to use/discuss ruote's design in order to explain the design and the design decisions around flor.
Flor may be thought of as a shrinking of ruote, a simplification. A workflow engine must be extremely robust, at least it must let executions be fixed with relative ease. That shrinking / simplification should go in that way.
executions, nodes, messages
Benjamin is mentioning among others, those three flor concepts, executions, nodes and messages. There is a flor glossary, it's currently incomplete. Those three concepts deserve some kind of explanation.
An execution is an instance of a flow. A flow is a [business] process definition. There can be many executions of a flow. You create an execution by handing a launch message to a flor scheduler. A launch message is an "execute" message. The two main messages in flor are "execute" messages and "receive" messages. The execute messages ensure the buildup of nodes, the receive messages accompany the termination of nodes.
Here is an example flow:
sequence
task 'alice' 'stage a'
task 'bob' 'stage b'
Executing it, in other words, creating an execution of it, starts with an "execute" message, with the given flow, translated into a[n abstract syntax] tree, being handed to the flor scheduler.
The scheduler will create a temporary component, an executor to run the execution. The executor will consider the initial execute message and create the corresponding node with a "nid" of "0" (root node). The node is a storage artefact, the executor then hands message and node to the "sequence" procedure, where the behaviour of a sequence is determined (execute children 0, wait for its receive message, execute children 1, wait..., when there are no more children, send receive message to parent node).
Execute messages build up the execution (seen by the addition of nodes), while receive message are symptoms of the execution building down (usually receive messages go hand in hand with the executor removing nodes from the execution).
I write that the executor is a temporary component because it only lives for the time of a session, when there are no more messages to proceed, the executor ends. When new messages show up, the scheduler will create a new executor who will pick up the execution where the previous executor left it (in the database).
The vanilla example of a "session" would be, following the flow above, the run from the sequence to its first child, the task emitted to the 'alice' tasker. When the "task" message has been handed to alice, there are no more messages to proceed, the session ends, the executor finishes.
a [hopefully] concrete example
Thanks to Asciinema and kinocompact, here is a run of the above flow. When the executions happen, there are summaries of the messages emitted to stdout, I hope it's not too confusing.
I extracted the messages for the three sessions fo the "rucho" execution. The "exe" lines are for "execute" messages. The "rec" lines are for "receive" messages. The "tas" lines are for "task" messages. Each of the below "ucho" lines are summaries of a single message. Note the node ids, 0, 00, 01, etc...
Here is the first session, where the execution is launched. It ends with 2 nodes (sequence 0 and alice tasker 0_0) and a task handed to alice. There are multiple "tas" messages since the executor discusses with the ganger to determine what tasker should receive this task labelled "alice".
I had better call those sessions "runs", as you can see in the logs, that's the word flor uses.
/--- run starts Flor::UnitExecutor 70115976477080 shell-cli-20171021.0830.mechulorucho
| {:thread=>70115976196240}
| {:counters=>{}, :nodes=>0, :size=>-1}
ucho 0 exe [sequence L2] [task,[[_att,[[_sqs,alpha,3]],3],[_att,[[_sqs,"s... m1s_" f.ret null vars:var0,_path,root,name
ucho 0_0 exe [task L3] [_att,[[_sqs,alpha,3]],3],[_att,[[_sqs,"stage a"... m2s1r1>1 from 0 f.ret null
ucho 0_0_0 exe [_att L3] [_sqs,alpha,3] m3s2r1>1 from 0_0 f.ret null
ucho 0_0_0_0 exe [_sqs L3] alpha m4s3r1>1 from 0_0_0 f.ret alpha
ucho 0_0_0 rec [_att L3] hp:_att m5s4r1>1 from 0_0_0_0 f.ret alpha
ucho 0_0 rec [task L3] hp:task m6s5r1>1 from 0_0_0 f.ret alpha
ucho 0_0_1 exe [_att L3] [_sqs,"stage a",3] m7s6r1>1 from 0_0 f.ret alpha
ucho 0_0_1_0 exe [_sqs L3] "stage a" m8s7r1>1 from 0_0_1 f.ret "stage a"
ucho 0_0_1 rec [_att L3] hp:_att m9s8r1>1 from 0_0_1_0 f.ret "stage a"
ucho 0_0 rec [task L3] hp:task m10s9r1>1 from 0_0_1 f.ret "stage a"
ucho 0_0 tas [task L3] hp:task m11s10r1>1 from 0_0 f.ret "stage a"
ucho 0_0 tas [task L3] hp:task m12s10r1>1 from 0_0 f.ret "stage a"
| run ends Flor::Logger 70115974783520 shell-cli-20171021.0830.mechulorucho
| {:started=>"2017-10-21T08:30:48.174253Z", :took=>0.019922}
| {:thread=>70115976196240, :consumed=>12, :traps=>0}
| {:counters=>{"runs"=>1, "msgs"=>12, "omsgs"=>0}, :nodes=>2, :size=>465}
\--- .
The executor ends, its run over, alice has its task. The execution (the sum of nodes) has been saved to the database.
As you've seen in the asciinema above, I then return this task to the execution (a "return" message placed in the flor scheduler database). The scheduler notices it, instantiates an executor, which removes the alice task node, sends a "rec" message to the sequence, which then sends an "exe" message to its 0_1 child, the bob task.
/--- run starts Flor::UnitExecutor 70115975852240 shell-cli-20171021.0830.mechulorucho
| {:thread=>70115975803940}
| {:counters=>{"runs"=>1, "msgs"=>12, "omsgs"=>0}, :nodes=>2, :size=>465}
ucho 0_0 ret [task L3] hp:task m13s_ f.ret "stage a"
ucho 0_0 rec [task L3] hp:task m14s_r2>2 f.ret "stage a"
ucho 0 rec [sequence L2] hp:sequence m15s14r2>2 from 0_0 f.ret "stage a" vars:var0,_path,root,name
ucho 0_1 exe [task L4] [_att,[[_sqs,bravo,4]],4],[_att,[[_sqs,"stage b"... m16s15r2>2 from 0 f.ret "stage a"
ucho 0_1_0 exe [_att L4] [_sqs,bravo,4] m17s16r2>2 from 0_1 f.ret "stage a"
ucho 0_1_0_0 exe [_sqs L4] bravo m18s17r2>2 from 0_1_0 f.ret bravo
ucho 0_1_0 rec [_att L4] hp:_att m19s18r2>2 from 0_1_0_0 f.ret bravo
ucho 0_1 rec [task L4] hp:task m20s19r2>2 from 0_1_0 f.ret bravo
ucho 0_1_1 exe [_att L4] [_sqs,"stage b",4] m21s20r2>2 from 0_1 f.ret bravo
ucho 0_1_1_0 exe [_sqs L4] "stage b" m22s21r2>2 from 0_1_1 f.ret "stage b"
ucho 0_1_1 rec [_att L4] hp:_att m23s22r2>2 from 0_1_1_0 f.ret "stage b"
ucho 0_1 rec [task L4] hp:task m24s23r2>2 from 0_1_1 f.ret "stage b"
ucho 0_1 tas [task L4] hp:task m25s24r2>2 from 0_1 f.ret "stage b"
ucho 0_1 tas [task L4] hp:task m26s24r2>2 from 0_1 f.ret "stage b"
| run ends Flor::Logger 70115974783520 shell-cli-20171021.0830.mechulorucho
| {:started=>"2017-10-21T08:36:50.418712Z", :took=>0.012553}
| {:thread=>70115975803940, :consumed=>14, :traps=>0}
| {:counters=>{"runs"=>2, "msgs"=>26, "omsgs"=>0}, :nodes=>2, :size=>500}
\--- .
The execution run ends as bob received a "tas" message. The execution has been saved to the database.
I then return the bob task to the execution with a "ret" message. The scheduler notices the message, instatiates an executor, which removes the bob task node and sends a "rec" message to the sequence 0. The sequence is supposed to send an execute message to its next child, but there are no more children, it's supposed to send a "rec" message to its parent node then. There are no parent node, the sequence being the root node. The execution ends.
/--- run starts Flor::UnitExecutor 70115974805760 shell-cli-20171021.0830.mechulorucho
| {:thread=>70115974734660}
| {:counters=>{"runs"=>2, "msgs"=>26, "omsgs"=>0}, :nodes=>2, :size=>500}
ucho 0_1 ret [task L4] hp:task m27s_ f.ret "stage b"
ucho 0_1 rec [task L4] hp:task m28s_r3>3 f.ret "stage b"
ucho 0 rec [sequence L2] hp:sequence m29s28r3>3 from 0_1 f.ret "stage b" vars:var0,_path,root,name
ucho rec m30s29r3>3 from 0 f.ret "stage b"
ucho ter m31s30r3>3 from 0 f.ret "stage b"
| run ends Flor::Logger 70115974783520 shell-cli-20171021.0830.mechulorucho
| {:started=>"2017-10-21T08:42:46.923942Z", :took=>0.414913}
| {:thread=>70115974734660, :consumed=>5, :traps=>0}
| {:counters=>{"runs"=>3, "msgs"=>31, "omsgs"=>0}, :nodes=>1, :size=>457}
\--- .
Benjamin, further questions via Twitter, the flor mailing list or the flor chat are welcome. I'll try my best to write a response blog post if necessary.
Thanks for asking.
20171013 Hiroshima.rb #058
Yesterday's evening we had Hiroshima.rb #058 at the Basset Café in West Hiroshima.
Due to the Rubykaigi 2017, we had paused for two months. We hope to go on with one Hiroshima.rb meeting per month.
Furukido-san wrote his own report of the event, he came in late and missed the first two talks though.
talks
Methods ending in "ect"
I went first and presented about methods ending in "ect" in Ruby. More about this and the end of this post.
Clean Code
Nishimoto-san talked about his new Safari Subscription. It seems O'Reilly is pushing its customers into Safari subscriptions instead of selling electronic books one by one.
Interestingly, videos are part of the bundle and Nishimoto-san got interested in the Clean Code videos made by Uncle Bob.
Nishimoto-san concluded with a set of good practices he picked up from the videos he viewed so far.
Elastic Beanstalk
Ishibashi-san went next and presented about the Rails application he built and is managing. He showed us how he is deploying them to Elastic Beanstalk and how he is using Vagrant locally for testing those deployments.
Ishibashi-san had already presented about his contact application, but this time the focus was on deployment and management.
Swift and Ruby
Guri-san was attending for the first to Hiroshima.rb, he also attended the RubyKaigi. He's currently studying in a technical university, he talked about the technologies he is using, technologies that are taught to him and the ones he'd like to explore on his own.
He is building a photo sharing application with a Ruby backend and a Swift frontend. I think he mentioned further applications, but I can't remember exactly.
Docker interests him, Nim (shame on me, I think it's the first time I learn about this one), Julia and also Hanami which he discovered during the RubyKaigi.
Webpacker and Elm
Adam-san had no slides but he was prepared and made a demonstration of Webpacker (may I say it's a frontend to Webpack?).
He went from a bare Rails application, showing the classical asset pipeline approach to packaging javascript assets to the Webpacker way.
Adam stepped then into using Elm and entrusting its compliation and packaging to Webpacker. We were all very interested in seeing Elm and noticing its resemblance to Haskell.
Favourite Ruby gems
Furukido-san presented to us a list of his favourite gems or at least gems he feels interest for.
I was happy to see Sequel in his list, I had just mentioned it in my talk.
I too share an interest for Trailblazer, I'm looking forward to see where it goes (I had included a link to a part of Trailblazer in my RubyKaigi talk).
As mentioned above, Furukido-san wrote a report about this 58th Hiroshima.rb meeting.
Giro di Rubykaigi
At the end of the RubyKaigi, Ando-san and friends organized a cycling tour starting in Onomichi U2. Mitsuda-san was one of the organizers and he presented about his experience of the event.
He showed to us a lot of pictures and explained what happened and who took part cycling.
Hiroshima Open Seminar 2017
Takata-san had arrived a bit late and ended up talking last.
He reminded us about the upcoming Open Source Conference 2017 in Hiroshima. He showed us the timetable of the conference. It is very crowded, a whole day with four tracks, a real bazaar.
It seems there will be a SciRuby-jp talk (about PyCall if I remember correctly).
my talk
I presented about [some] methods ending in "etc" in Ruby.
I favour collect over map, select over find_all, etc.
The end of the talk focuses on a [joke] Ruby gem named ect that adds four "ect" methods to Ruby (well 2 aliases and two trivial methods).
class Object
alias inflect tap
def deflect
yield(self)
end
end
module Enumerable
alias bisect partition
def dissect
inject([]) { |a, elt| (a[yield(elt)] ||= []) << elt; a }
end
end
There are usage examples for those four methods in ect's readme.
Special mention for Ishibashi-san who mentioned Ruby's #respect method.
20171004 RubyKaigi 2017

The RubyKaigi Circus came in our good town of Hiroshima for its 2017 edition last week.
I was lucky enough to be a speaker, although, initially, I merely wanted to be a helper.
My first RubyKaigi was the 2007 edition. Time flies.
pre-kaigi
The RubyKaigi team came to visit Hiroshima around March. They especially visited the International Conference Center. It is very affordable compared to similar offers in the Greater Tokyo.
They contacted the local Hiroshima Ruby people and requested for 3 to 4 local organizers, to support them in everything Hiroshima. Thus, Himura-san, Takata-san, Kitadai-san and Nishimoto-san were chosen.
At that point I realized that our local Ruby community was languishing and, with the benediction of our benevolent leader Himura-san, I rebooted Hiroshima.rb, we're since trying to meet every month for a Lightning Talk gathering. We had a break around the RubyKaigi, but we start again in October.
A few weeks before the conference, the helper staff was recruited, most of the Hiroshima Rubyists got in as well as students from the local tech university. From Tokyo, I was happy to see Paul "Doorkeeper" McMahon, I hadn't met him for 7 years I think. I'm happy to see that Doorkeeper is striving (and used for ticketing the RubyKaigi itself). Paul, thanks for coaching Adam on his first RubyKaigi!
The day before the Kaigi a typhoon swept across the islands but, as usual, there was no direct hit on Hiroshima, it passed south. The conference days, right after the storm were thus beautiful.
navigating through the talks
#RubyKaigi にカープファンも参加してますw pic.twitter.com/ewtzFojesi
— tkt@ホ゜ッピンQ&キミコエ応援中 (@takatayoshitake) September 18, 2017
Since I was talking right before the lightning talks on Tuesday afternoon, I spent the first days half-listening, half-preparing my own talk.
I favoured the underdog talks (there weren't many of them), that drove me towards the Cosmos room and sometimes the Dahlia room.
The honours of the Keynote went to Nobu-san. I remember meeting him 10 years ago. He had told me he is from the Tochigi prefecture that had made me dream about Nikko and the frozen valleys I had visited there the previous winter. The RubyKaigi team assured us that it was one of his first time to speak in public, he did well!
The next talk on my list was Mapping your world with Ruby, about SafeCast, an invaluable system in our Fukushima days.
TextBringer is a text editor named after Stormbringer. I love it when a developer takes a piece of wood and carves an essential tool out of it, I love it when developers write text editors.
The Gemification for Ruby 2.5/3.0 was very interesting. In reverse, sometimes I'd love to have Concurrent-Ruby integrated in the standard library, but that's not my business.
Spring is gone, but it was still time for Hanami. I said hi to the speaker and got my sticker, I will give it to daughter #1.
The Goby talk was nice. Ruby certainly is an inspiration for many languages, we need to update the genealogy tree. Kudos to Stan.
I skipped the "Ruby committers vs the World". I also skipped next day's keynote.
My second day started with @yhara-san's talk about Ruby, Opal and WebAssembly. The presentation featured two or three in-browser demos and the slides were fun to follow.
I then attended What visually impaired programmers are thinking about Ruby? by local organizer Nishimoto-san. His conclusion indicated that Ruby fares not that bad. He took us in a world of braille terminals and screen-reading tools. Text is king, visual programming must be quite out of question. My eyes get hammered every day, I might become an old programmer that is visually impaired and that is making me think.
Asynchronous and Non-Blocking IO with JRuby was a solid talk. The glimpses shared about the working of the JRuby team were very interesting.
The next Cosmos talk, Food, wine and machine-learning, filled the room. I got mislead by the "teaching a bot to taste" subtitle, it was rather "teaching a bot to match food and wine". Tasting wine is so subjective, friends make the wine great.
It was then time for my talk, see below.
The lighting talks were wonderful. I have to say that I dream of a Regional RubyKaigi made up only of lightning talks, delivered quickly in Japanese or English or plain Ruby, punctuated by espressi.
The next morning, I had to release a piece of software for a customer and couldn't attend to the first volley of presentations.
The talk by Tagamori-san, Ruby for distributed storage system, was exciting. I like what Treasure Data is doing and I especially follow digdag among all their tools.
There was then a heavy legacy redux talk: Ruby parser in IRB 20th anniversary. Itoyonagi-san seems to have done a bit of that work in an alpine shack near the top of a Swiss mountain. I forgot to ask which one :-(
What I like about the next presentation I attended to is its demonstration of a combo that, I think, works wonders: the Ruby guy and the Business guys. I am not thinking technical co-founder and business co-founder, I'm simply thinking about the business team/line and its weaponsmith. Ruby unceremouniously and concisely involved in the tools to achieve business goals. Ruby in office time reboot.
I then had to leave the RubyKaigi to go and welcome my parents who were visiting for two weeks.
All the talks and presentation materials are available directly from the RubyKaigi 2017 Schedule. That'll let me catch up on what I missed and what I misunderstood.
flor hubristic interpreter
Right before the Lightning Talks, I gave my flor talk. The video is on the right.
The Cosmos room was packed for the previous talk and most of the people left after it ended.
I could have talked about rufus-scheduler but I think there's nothing interesting in a long history of maintenance and slow rework. It's used here and there, the star count goes up, people complain, I fix things the best I can.
The only thing I could talk with some passion is flor and my hubristic quest for a workflow tool that'd made sense to me. I decided to have some 20% of my time spent in "flosh", the flor shell, to show the operating system nature of flor and that went OK.
I had asked Nyoho-san to present me. Generally RubyKaigi organizers were presenting the speakers but sometimes non-staff people did the presentations. I wanted to have an organizer and especially a local organizer doing the introduction. Ishibashi-san lent his Carp cap to Nyoho-san for him to deliver his introduction flawlessly. Unfortunately Nyoho-san doesn't appear on the video.
Flor is an interpreter for a funny language that is somehow Lisp-like. It's slow, but fast enough, especially when driving human's work flows. I try to build it as an operating system for business processes.
I was torn between "hey, it's a RubyKaigi, you have to talk about something tightly Ruby-related" and "whatever, it's Ruby-related and I'm passionate about it". Not sure if the passion helped. I think I missed the chance to show that Ruby is great for concisely implementing the tasks that make up a business process, and that flor is merely tapping into that greatness.
I am still nostalgic for flon, the C prototype to flor. Tiny servers driving business processes among shellish taskers.
There was one gentleman in the crowd with a Carp cap and t-shirt, I wanted to thank him for flying the local colours but I got diverted by questions.
I was happy delivering this speech. I hope it wasn't too boring. It motivates me anyway to go on developing flor.
thanks
Many thanks to Matsuda-san, Kakutani-san, Aki-san, Himura-san, Takata-san, Kitadai-san and Nishimoto-san. And to Paul-san, Adam-san, Mitsuda-san, Ishibashi-san, Ando-san and Furukido-san. Thanks also to the GetHiroshima people for supplying the RubyKaigi with their guide and their map to help foreign visitors navigate through Hiroshima.
20170814 chruby in Hiroshima
Back in June, I presented about chruby and ruby-install at Hiroshima.rb #056. My slides are available on Speaker Deck.
Yesterday, Nishimoto-san explored chruby and wrote a blog post about it: https://ja.nishimotz.com/chruby. I like how he went further, installing a Ruby version manually, placing it in /opt/rubies/ruby-2.4.1 so that chruby sees it and then tasked himself with installing the Yard gem for this new Ruby.
My next step after installing a Ruby is to do gem install bundler and then I don't touch gem much, except when pushing a Ruby gem out (I have gem build and gem push wrapped in a make push at that point).
Thanks to Nishimoto-san for this post, full of hints.
20170714 tiny delicious clone for Hiroshima.rb 057
For the first iteration of Hiroshima.rb "reboot" (#056), I had presented about chruby. (Sorry no blog post).
This second iteration of Hiroshima.rb once again took place at the Basset Café.
We were eight and each of us had to present, a lightning talk or simply a few words.
Bussaki-san presented about pycall and showed examples of it wrapped in a Jupyter notebook. This PyCall looks very interesting. It bridges Ruby to powerful Pyhton libraries like NumPy, seaborn, etc.
Mitsuda-san showed us how to run Jupyter Docker images with Python and Ruby enabled. He then proceeded to show us a few Ruby quizzes exposed in Jupyther notebooks. He had already presented about this subject during the last Sugoi Hiroshima with Python but at that point, hadn't explored Ruby in the notebooks.
Kitadai-san built a Sinatra service interfacing one of Hiroshima's universities CMS system. He was a bit puzzled because only HEAD requests came through to his Sinatra service, GETs and POSTs were nowhere to be seen. Interesting investigation ahead.
Nishimoto-san had presented about a Disco challenge during the last Sugoi Hiroshima with Python. He showed us a solution to the question two of that challenge, but this time in Ruby. (Here are two of my solutions to this challenge).
Ishibashi-san presented us an application he's building based on Ruby on Rails. Employees of his company access it via their iPads to receive assignments. Those assignments are controls and repairs to perform for customers. Once the assignment is done, the employees report completion once again via the iPad (and the Ruby on Rails application). Ishibashi-san also presented the book series he learns Rails from, it's the Ruby on Rails series from Kuroda-san. Interestingly, this author is now also writing about Elixir.
Adam-san taught us about Ruby's Enumerator. He recapitulated the methods provided by this class. It had a nice overlap with the techniques presented by Nishimoto-san for his programming challenge.
Takata-san, as one of the organizers of the upcoming RubyKaigi 2017 is currently listing all the restaurants at walking distance from the conference center. He showed us the tools he's using in his data gathering endeavour.
Since Kitadai-san recently attended a presentation by Garr Reynolds, the author of Presentation Zen, he stood up and talked about the things he enjoyed and learned during this presentation. Mitsuda-san initiated a comparison between Presentation Zen and the Takahashi Method, but Kitadai-san told us that Garr Reynolds advocates storytelling and is putting back light on kamishibai as a way of presenting.
I talked about a micro del.icio.us clone I built on top of Sinatra:
It's called deli.
20170629 yahoo proxy with python
I am not a Python programmer, but I participated to last night SugoiHiroshima (#すごい広島) and I had brought with me a deck of slides about a small proxy to Yahoo Finance that I wrote as a toy example.
At the end of the deck, I'm giving pointers to 12factor.net /ja/, runit and providing a quick configuration example for a Nginx reverse proxy to put in front of that service.
20170519 hail to the King Arduin
connecting
I got an Arduino Nano clone for ~ USD 3.5 and attempted to connect it to my OSX Yosemite laptop.
At first, no lights, my micro-USB cable was dead. Found another one and the Nano lit up.

But the Arduino IDE was not seeing the board. I was only seeing the USB modem serial ports in the selection.
After various tries downloading and installing the ch34X driver, I could talk with the board, but had random kernel panics.
I finally came across this Github project with a patched version of the driver. The project says "Sierra", but I tried the advertised:
$ brew tap mengbo/ch340g-ch34g-ch34x-mac-os-x-driver https://github.com/mengbo/ch340g-ch34g-ch34x-mac-os-x-driver
$ brew cask install wch-ch34x-usb-serial-driver
and it then worked flawlessly on my Yosemite OSX, with the cu.wchusbserial1410 that appears when the Nano board is connected.
developping
The Arduino IDE is nice and all, it provides access to a wealth of libraries and example, but a Vim person like me was soon feeling slowed by the editor.
You still need the Arduino IDE around, but you can use an Arduino-Makefile to stay in the command line.
At first, I tried to work with this Makefile following in the instructions behind the link in the project description, but that was an error.
Following the project readme is the path to the success.
$ brew tap sudar/arduino-mk
$ brew install arduino-mk
$ pip install pyserial
Then I included a link to the template makefile
ARDUINO_DIR:=/Applications/Arduino.app/Contents/Java
ARDMK_DIR:=/usr/local/opt/arduino-mk
AVR_TOOLS_DIR:=$(ARDUINO_DIR)/hardware/tools/avr
MONITOR_PORT:=/dev/cu.wchusbserial1410
BOARD_TAG:=nano
BOARD_SUB:=atmega328
include /usr/local/opt/arduino-mk/Arduino.mk
I wrote my serial_blink.ino thus
const unsigned int LED_PIN = 13;
const unsigned int BAUD_RATE = 9600;
void setup() {
pinMode(LED_PIN, OUTPUT);
Serial.begin(BAUD_RATE);
}
void loop() {
if ( ! Serial.available() > 0) return;
int c = Serial.read();
if (c == '0') {
digitalWrite(LED_PIN, LOW);
}
else if (c == '1') {
digitalWrite(LED_PIN, HIGH);
}
}
and uploaded it with make upload, hit the serial console with make monitor and was able to turn the LED on with a 1 and off with a 0.
My small start project is at https://github.com/jmettraux/serial_blink.
20170331 my "Open in Vim" OSX service
Many times, when contemplating a grep or a rspec output, I wish I could wink at a certain line and make it open the target file at the appointed line.
I try to work with the keyboard with as little as possible trackpad or mouse gesticulations, but since I'm "contemplating", my rhythm is already lost. So I allowed myself a right-click service.
I double click on the target line in the Terminal.app, right-click then select "Open in Vim" in the contextual menu and it opens the file at the "colon" line for me.
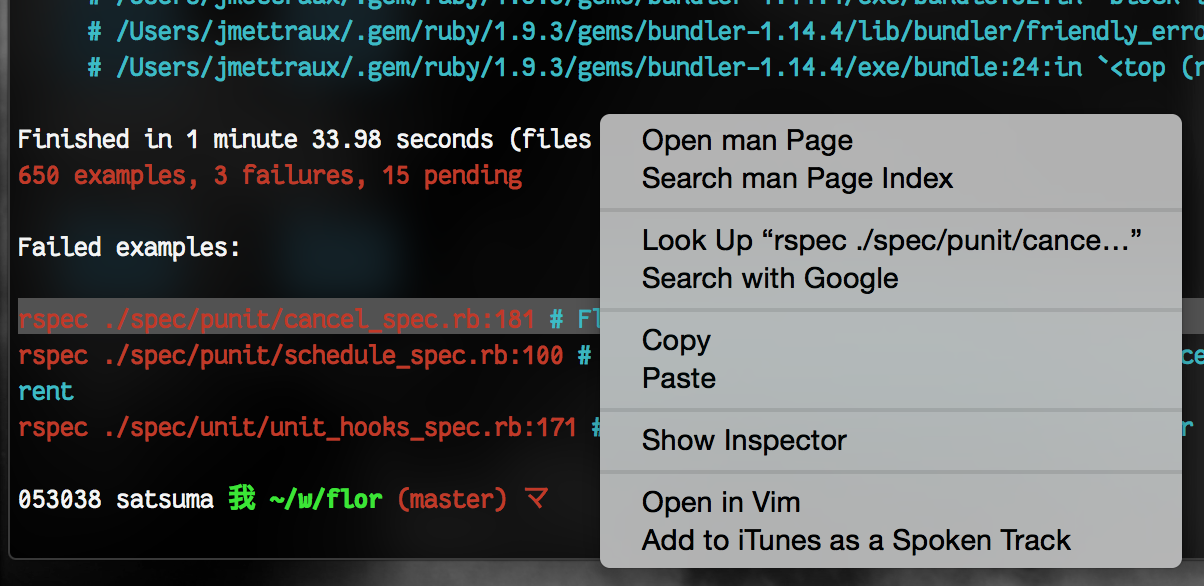
How does it look like behind the scene?
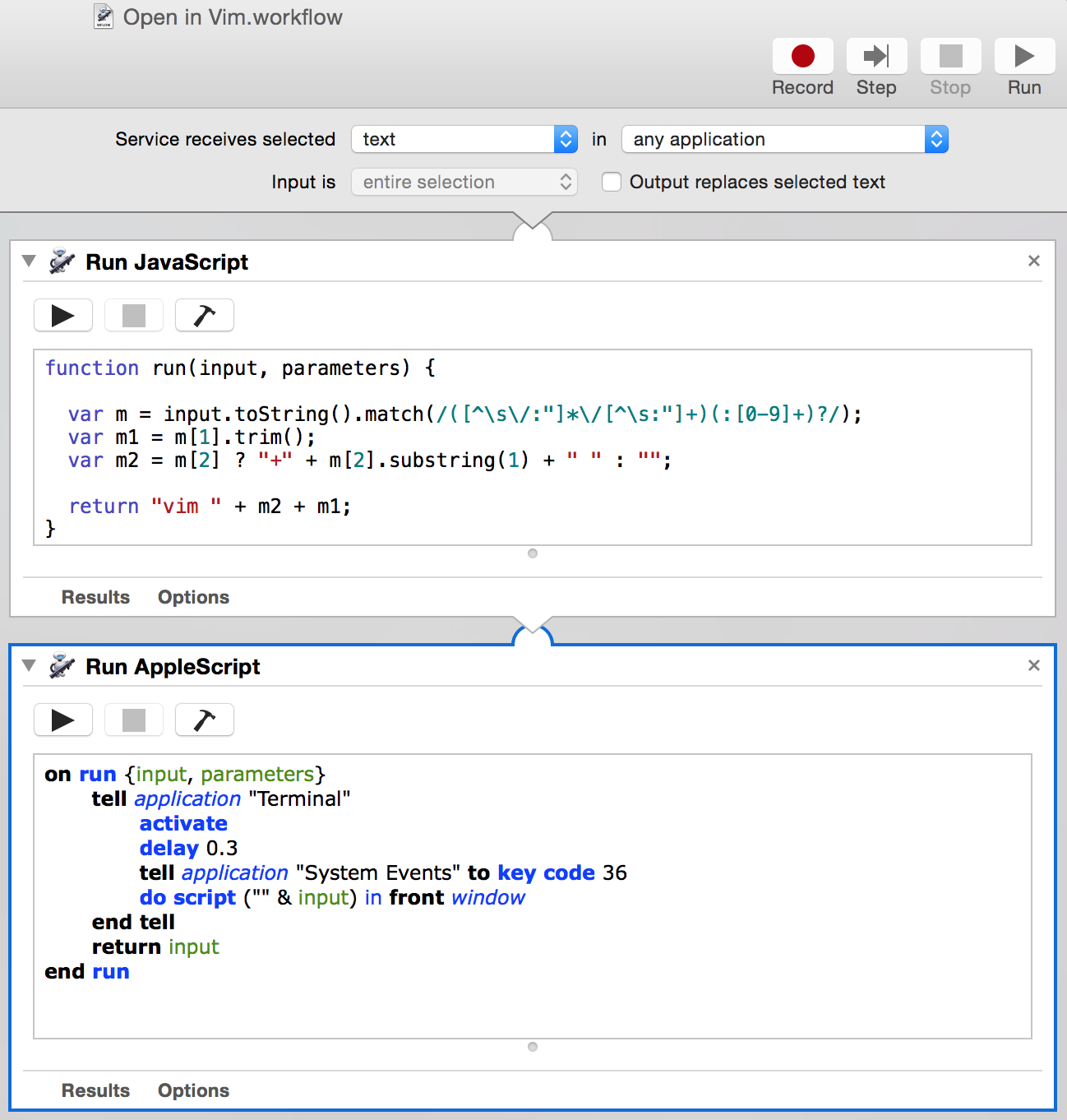
It's an Automator (that robot icon) service, saved under the name "Open in Vim" that chains a Javascript and an Applescript piece of code.
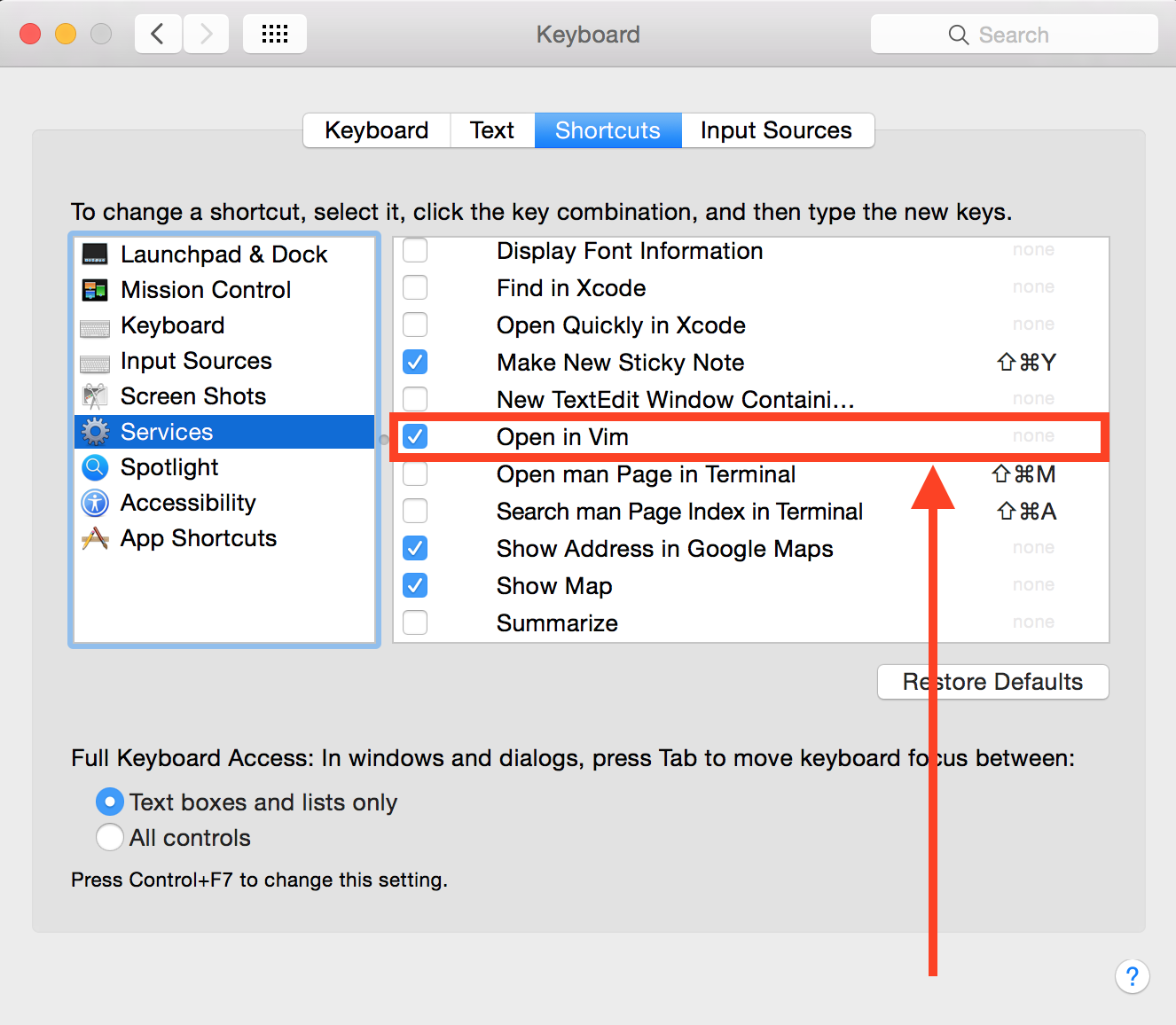
The service has then to be bound from the System Preferences / Keyboard / Shortcuts.
One could even tie a keyboard shortcut for it from there.
Here are the two pieces of code, the Javascript one:
function run(input, parameters) {
var m = input.toString().match(/([^\s\/:"]*\/[^\s:"]+)(:[0-9]+)?/);
var m1 = m[1].trim();
var m2 = m[2] ? "+" + m[2].substring(1) + " " : "";
return "vim " + m2 + m1;
}
and the Applescript one:
on run {input, parameters}
tell application "Terminal"
activate
tell application "System Events" to key code 36
delay 0.3
do script ("" & input) in front window
end tell
return input
end run
Update 2017-03-31
For those of you using iTerm2, here is a post by Luca Guidi on how to do it: "Click on stack trace to open a file with NeoVim".
Update 2017-04-01
Made Javascript more robust.
Update 2017-04-02
Made Javascript more robust and made sure to send a preliminary return key to the terminal before calling Vim.
Update 2018-06-06
Made Applescript wait before running the vim +... script.
20170321 zero indent
As I wrote earlier, I don't use a debugger, lately I've started placing the puts, p and pp I use to help me develop at indentation zero, like this:
def self.get_tzone(o)
p [ :gtz, o ]
return nil if o == nil
return local_tzone if o == :local
return o if o.is_a?(::TZInfo::Timezone)
if o.is_a?(Numeric)
i = o.to_i
sn = i < 0 ? '-' : '+'; i = i.abs
hr = i / 3600; mn = i % 3600; sc = i % 60
o = (sc > 0 ? "%s%02d:%02d:%02d" : "%s%02d:%02d") % [ sn, hr, mn, sc ]
end
return nil unless o.is_a?(String)
return ::TZInfo::Timezone.get('Zulu') if o == 'Z'
z = (@custom_tz_cache ||= {})[o]
return z if z
z = (::TZInfo::Timezone.get(o) rescue nil)
return z if z
z = get_offset_tzone(o)
return z if z
nil
end
The code that is here for debugging immediately stands out. I can easily locate it with the /^p regular expression as well.
Example taken out of et-orbi.
20161128 rufus-scheduler 3.3.0 released
I have just released rufus-scheduler 3.3.0.
Rufus-scheduler is a job scheduling (at, in, every, cron) library available as a Ruby gem. It is not meant as a cron replacement, it lives within the Ruby process using it and dies with it.
Why the jump from 3.2.x to 3.3.x? It's because of a mistake I made: I was relying on ENV['TZ'] to get timezoned Time instances. It works fine and cuts the dependency on the tzinfo gem, but when you're working with multiple threads and one is setting ENV['TZ'] to Europe/Helsinki while another is setting it to America/Houston, both might end up with Time instances in Houston or Helsinki. Chaos.
This rufus-scheduler 3.3.0 brings back the tzinfo dependency and uses it to support its Rufus::Scheduler::ZoTime class. Instances of ZoTime quack like if they were Ruby Time instances but keep their zone as an instance of TZInfo::TimeZone.
Should problems appear after an upgrade to 3.3.0, please fill a clear and detailed issue at https://github.com/jmettraux/rufus-scheduler/issues.
This ENV['TZ'] problem was pointed out (gh-220) by Musha Akinori. Many thanks to him!
A new feature made it into this 3.3.0, it was requested/contributed by Piavka in gh-214. It's a Rufus::Scheduler::Job#trigger_off_schedule method. It lets you trigger a job, off of its schedule. If, during the off schedule run, the job is started "in schedule", overlap settings kick in. Off-schedule or in-schedule, calls to Job#running? will return true. It has its uses with repeat jobs.
This release also contains two fixes. One for .parse_to_time vs Date instances (gh-216), thanks to Nicolás Satragno. And one for "day 0 cronlines" (gh-221), thanks to Ramon Tayag.
Thanks again.
20160905 patterns at Hiroshima Lightning Talks
I gave a lightning talk about patterns at the Hiroshima Lightning Talks gathering.
I started by showing my GR1 ruck and pitching the two "patterns" it sports that are important for me:
- Laptop compartment separate from main compartment
- Lays completely flat and opens almost like a suitcase


I then went further and switched to software patterns and the well known Elements of Reusable Objected-Oriented Software, from there I shew two further books but then switched to the origin of the patterns in the Pattern Language movement (some say "permatecture").
Some people with only peripheral knowledge of programming think that only the GoF book exists and that quizzing a programmer about them is a valid "interview" technique. Some of the patterns in there are object-oriented language specific and when you dwell back in functional programming (back from computer techniques into science), those patterns are gone with the wind. The patterns in the books beyond that book are more important.
Here are the slides, they are rough, they were only pillars to my talk.
The building picture are from the Eishin Campus that Christopher Alexander with and for the teachers and students there.
My rucksack was the first point of the talk because it contained all the books described in the talk, I could then hand the books to the participants and let them get a feel for the volumes.
Among the Christopher Alexander books, my current favourite is A Pattern Language, I get lost in it, trying to absorb the wisdom it distils. As a programmer I love to grow interesting, useful, nice pieces of sofware, but I also crave for places where I can sit or stand and let that growing happen.
There is a great documentary about Christopher Alexander on YouTube: "Life cannot be produced from a drawing, life can only be produced from a process" (minute 3:40).
20160504 rufus-scheduler 3.2.1 released
I've just released rufus-scheduler 3.2.1.
Rufus-scheduler is a Ruby gem for scheduling pieces of code. You instantiate a scheduler and you tell it after how long you want a block of code to run or how often you want it to run.
require 'rufus-scheduler'
scheduler = Rufus::Scheduler.new
scheduler.in '3h' do
# do something in 3 hours
end
scheduler.at '2030/12/12 23:30:00' do
# do something at a given point in time
end
scheduler.every '3h' do
# do something every 3 hours
end
scheduler.cron '5 0 * * *' do
# do something every day, five minutes after midnight
# (see "man 5 crontab" in your terminal)
end
scheduler.join
# let the current thread join the scheduler thread
This 3.2.1 release mostly brings negative weekdays to cron strings. It lets you write crons like:
require 'rufus-scheduler'
scheduler = Rufus::Scheduler.new
scheduler.cron '5 0 * * 5L' do
# do something every last Friday of the month, at 00:05
end
scheduler.cron '5 0 * * 4#-2,4#-1' do
# do something every second to last and last Thursday of the month, at 00:05
end
#
# or
#
scheduler.cron '5 0 * * thu#-2,thu#-1' do
# do something every second to last and last Thursday of the month, at 00:05
end
scheduler.join
Many thanks to all the people that contributed to the development of rufus-scheduler.
20160227 dot errors rspec custom formatter
I work with two terminals side by side, a wide one of the left for running and an 80 columns one on the right for editing. The left one often gets hidden behind a browser window but I can easily bring it back with a keyboard shortcut.
My Ruby coding is a long back and forth between those two terminals, write some code on the right, run one or more specs on the left, read the error messages, fix on the right... It happens without clicking, only keyboard interactions.
I wanted to navigate immediately from an error to its location in its spec file. At first, I was thinking about letting the click on the spec/nasty_spec.rb:66trigger something but it would kill the "only keyboard interactions" joy.
I came up with a custom Rspec formatter.
# ~/.bash/rspec_dot_errors_formatter.rb
class DotErrorsFormatter
RSpec::Core::Formatters.register self, :dump_failures
def initialize(output)
@output = output
end
def dump_failures(notification) # as registered above
notification.failure_notifications.each do |fn|
m = fn.formatted_backtrace.first.match(/\A([^:]+_spec\.rb:\d+):in /)
@output << m[1] << "\n"
break
end
end
end
./spec/p/val_spec.rb:78 ./spec/z/applications_spec.rb:92
I placed this rspec_dot_errors_formatter.rb file in my .bash/ directory and made sure my usual bxs alias includes this formatter when calling rspec:
alias bxs="bundle exec rspec \
--require ~/.bash/rspec_dot_errors_formatter.rb \
--format DotErrorsFormatter --out .errors \
--format d"
Note how I require the source file containing the custom formatter, then ask for it via --format, ensure its output is piped to .errors thanks to --out and then fall back to my default formatter d (for "documentation") followed by nothing. The --out is only for the preceding --format.
When running my specs, it will write down in a file named .errors the error locations in the specs.
I combined that with my ListFiles() function in Vim and get my list of error location beween my list of open buffers and of recently opened files:

I can now navigate to the "== .errors" section and jump directly to the error in the spec.
The next refinement will probably consist in mining each failure stacktrace for relevant file locations in the source itself, not in the spec source.
2016-12-05 update: let the ~/.bash/rspec_dot_errors_formatter.rb script add to .errors only the first _spec.rb files it encounters in the backtraces
20160222 vim :ListOld
The initial version of this post was about a ListOld function. After a few days, I changed my mind about it and rewrote as ListFiles, including current buffers and recently opened files in a single "view". The original post is still visible.
I use Vim as my main text editor. It's ubiquitous. I have a minimal .vim/ setup. It moves around with me easily, as long as I have ssh and git, I can get comfortable on a host very quickly.
I needed a way to access the most recently updated files. :bro old is painful to use.
Here is a vimscript function that pipes the output of :bro old in a file then lets you roam in it with j and k and then hit <space> to open a file. Use the standard ctrl-6 or ctrl-^ to get back in the file list.
It also outputs the result of :buffers, so you're presented with a list of currently open buffers followed by a list of recently opened files. I find it convenient for quickly navigating or getting back into context.
function! s:ListFiles()
exe 'silent bwipeout ==ListFiles'
" close previous ListFiles if any
exe 'new | only'
" | only makes it full window
exe 'file ==ListFiles'
" replace buffer name
exe 'setlocal buftype=nofile'
exe 'setlocal bufhidden=hide'
exe 'setlocal noswapfile'
exe 'setlocal nobuflisted'
exe 'redir @z'
exe 'silent echo "== recent"'
exe 'silent echo ""'
exe 'silent bro ol'
exe 'redir END'
exe 'silent 0put z'
" list recently opened files, put at top
exe 'redir @y'
exe 'silent echo "== buffers"'
exe 'silent echo ""'
exe 'silent buffers'
exe 'redir END'
exe 'silent 0put y'
" list currently open buffers, put at top
exe '%s/^\s\+\d\+[^\"]\+"//'
exe '%s/"\s\+line /:/'
exe 'g/^Type number and /d'
exe 'g/COMMIT_EDITMSG/d'
exe 'g/NetrwTreeListing/d'
exe 'silent %s/^[0-9]\+: //'
" remove unnecessary lines and ensure format {filepath}:{linenumber}
call feedkeys('1Gjj')
" position just above the first buffer, if any
setlocal syntax=listold
" syntax highlight as per ~/.vim/syntax/listold.vim
nmap <buffer> o gF
nmap <buffer> <space> gF
nmap <buffer> <CR> gF
"
" hitting o, space or return opens the file under the cursor
" just for the current buffer
endfunction
command! -nargs=0 ListFiles :call <SID>ListFiles()
nnoremap <silent> <leader>b :call <SID>ListFiles()<CR>
"
" when I hit ";b" it shows my list
The original is at https://github.com/jmettraux/dotvim/blob/fe1d1c3f/vimrc#L346-L390.
Here is an example output:
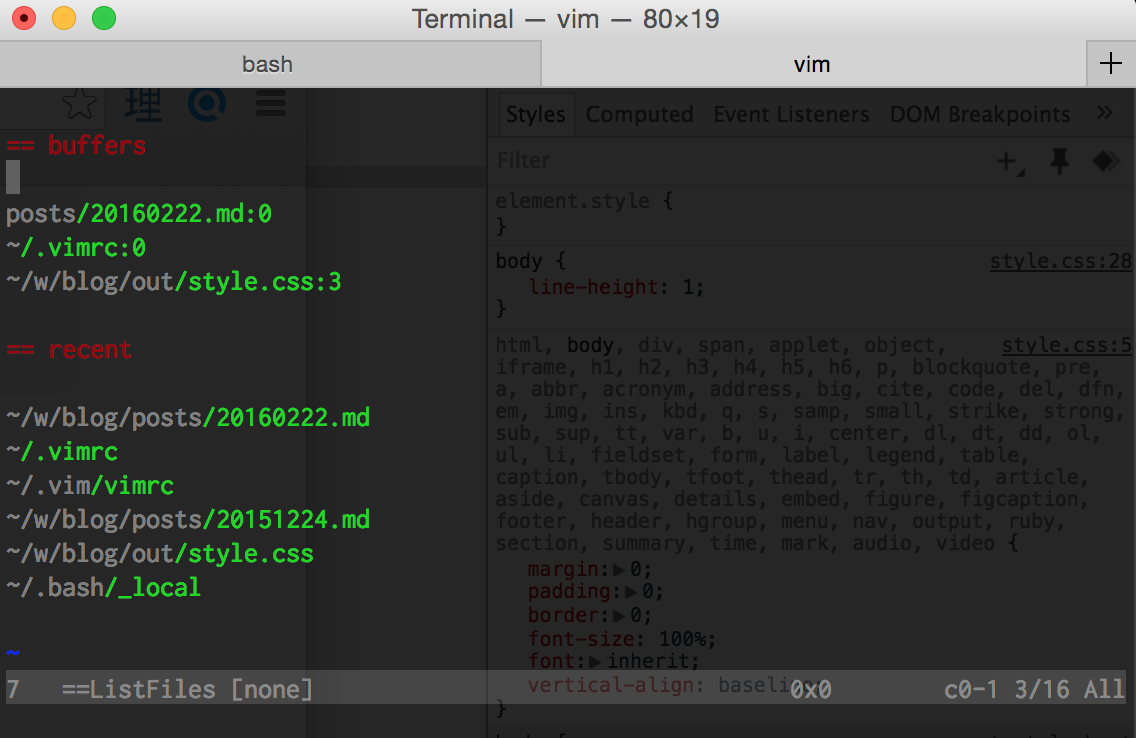
I move up and down with k and j and hit space to open the file under the cursor. I hit ctrl-6 (;; in my setting) to get back to the list of files.
I also added:
alias vo='vim -c "ListFiles"'
.bashrc so that vo fires up Vim directly in this list of files.
This script is condensed from a series of google searches and stackoverflow scans. I felt like quitting in the middle, but there is always an answer somewhere that unlocks it all.
20160210 radial and flon
to Ruby
I'm currently reworking flon in Ruby. I might use it for a customer, hence this preparatory work. I did a first pass at flor but I noticed that I was copying too much.
This effort towards Ruby is interesting. I had a need for a parsing tool so I ported flon's aabro to Ruby as raabro and since I also needed it client-side, I ported it again to Javascript as jaabro.
My old rufus-mnemo became flon's mnemo. For this Ruby port, I didn't re-use rufus-mnemo but ported mnemo back to Ruby as munemo.
These ports aren't part of the "I was copying too much" complaint I emitted above. I had simply noticed that I was porting flon one to one to Ruby and I felt uneasy about it as it progressed.
a radial core to flon
Looking back a flon itself, I was quite happy at the libraries I had built to support it. I was telling myself: so, I'm building an interpreter, all this difficult C will be hidden behind it and life will be good. I was thinking about the fun radial language I was stashing together for flon, a language strong at JSON.
I started to wonder: what if the flon business logic was written in radial itself?
I started prototyping a core radial interpreter and I named the project flar.
This core would be a minimal, non-concurrent radial interpreter, a core for flon and flor (Ruby flon). The non-core instructions, like "concurrence", "task" and the non-core attributes like "timeout", etc would be implemented as libraries (either radial, either C or Ruby depending on the target).
By non-core, I think workflow-esque stuff. The core language would be a limited yet funny programming language.
That's the plan. I try to devote one or two hours per day to it. It feels right for now.
20160205 hyperbooks
Books reference each other, directly or indirectly. You can now spend a life spidering from one book to the other.
Are there starting points? Certainly, the Illiad, the Epic of Gilgamesh and more.
At some points in the history of litterature there has to be books that bridge between the Illiad and the I Ching (even before the Man in the High Castle).
Then, all those who toil away at writing new books that echo the voice of the old bards.
20160128 familiarity
A man should avoid displaying deep familiarity with any subject. Can one imagine a well-bred man talking with the airs of a know-it-all, even about a matter with which he is in fact familiar? ... It is impressive when a man is always slow to speak, even on subjects he knows thoroughly, and does not speak at all unless questioned.
Kenkō "Essays in Idleness" (79) As translated by Donald Keene
20160111 banausic occupations
Very good, Critobulus; for to be sure, the so-called banausic occupations are scorned and, naturally enough, held in low regard in our states. For they spoil the bodies of the workmen and the foremen, forcing them to sit still and stay indoors, and in some cases to spend the whole day by the fire. As their bodies become womanish their souls lose strength too. Moreover, these so-called banausic occupations leave no spare time for attention to one's friend and city, so that those who follow them are reputed bad at dealing with friends and bad defenders of their country.
Socrates to Critobulus in Xenophon's Oeconomicus (3.15-4.3)
20151231 munemo 1.0
munemo is a rewrite of rufus-mnemo. The first rewrite was actually in C as mnemo, munemo is a port of mnemo from C to Ruby.
I use munemo and its siblings to turn integers into somehow rememberable words. The rememberable attribute usually has to span a debug session, as I am manually scanning a set of grepped log files for patterns. It helps me to have words I can say out loud instead of numbers. It also helps (not always) when transmitting an identifier over the phone to someone else.
Rufus-mnemo started with the japanese syllables, but mnemo and munemo work with a wider index, 100 syllables, and unlike rufus-mnemo they don't accept wovels on their own.
Munemo exposes two methods, here they are:
# Munemo.to_s(i)
Munemo.to_s(0) # => 'ba'
Munemo.to_s(1) # => 'bi'
Munemo.to_s(99) # => 'zo'
Munemo.to_s(100) # => 'biba'
Munemo.to_s(101) # => 'bibi'
Munemo.to_s(392406) # => 'kogochi'
Munemo.to_s(25437225) # => 'haleshuha'
Munemo.to_s(-1) # => 'xabi'
Munemo.to_s(-99) # => 'xazo'
Munemo.to_s(-100) # => 'xabiba'
# Munemo.to_i(s)
Munemo.to_i('blah blah blah') # => ArgumentError: "unknown syllable 'bl'"
Munemo.to_i('xabixabi') # => ArgumentError: "unknown syllable 'xa'"
Munemo.to_i('munemo') # => 475349
Munemo.to_i('yoshida') # => 947110
Munemo.to_i('bajo') # => 34
Munemo.to_i('xabaji') # => -31
Munemo.to_i('tonukatsu') # => 79523582
I wish you a happy new year!
20151229 small, custom-built interpreters
There's not much personal appeal to a Z80 emulator, but many applications I've written have small, custom-built interpreters in them, and maybe I didn't take them far enough. Is all the complaining about C++ misguided, in that the entire reason for the existence of C++ is so you can write systems that prevent having to use that language?
20151228 released rufus-scheduler 3.2.0
I have just released rufus-scheduler 3.2.0.
Rufus-scheduler is a job scheduling (at, in, every, cron) library available as a Ruby gem. It is not meant as a cron replacement, it lives within the Ruby process using it and dies with it.
The switch from 3.1.x to 3.2.x is motivated by the change worked on with @Korrigan. "every" schedules now more carefully stick to their "@next_time".
There is also a little bit of caching that got added to CronLine to prevent computing frequencies again and again when scheduling cron jobs.
Happy new year!
20151227 blank in the thinking
I'm an avid reader of Jacqueline de Romilly. She wrote a serie of essays about the health and the evolution of the french language. Here is a quote:
(...) Le blanc dans l'expression correspondait, je le crains, à un blanc dans la pensée. Car une impression globale et vague ne peut se préciser qu'à l'aide des mots, de leur distinction, de leur emploi délibéré et contrôlé. On pense avec des mots. On distingue les notions avec des mots. Le language est, en effet, l'instrument même de la pensée, et le seul moyen de lui donner des contours fermes."
"Dans le jardin des mots" Jacqueline de Romilly
Let me make an attempt at a translation:
(...) The blank in the sentence corresponded, I fear, to a blank in the thinking. A global and vague impression can only be refined thanks to words, their distinction, their deliberate and controlled use. We think with words. We distinguish notions with words. The language is, in fact, the instrument of thought, and the only mean to give it a firm outline.
20151226 I don't use a debugger
I spiral around the problem with a test, the smallest test possible that demonstrates the symptom of the bug.
Once I have my test, I go through a phase of analysis where I add print or log statements to see what is going on and find the cause of the bug. I run the test and add/modify the print statements in loop until I understand the cause.
Once the cause is found, it's time for the fixing phase. Again, running the test and modifying the code, but this time until the bug is fixed.
The next phase is running the test suite or a relevant subset of it to make sure the fix didn't break something elsewhere.
The print/log statements introduced in the first phase are slowly discarded in the second phase. Sometimes they stay, but commented out.
I like to leave commented out variants or explanations, for when I come back to the code in later developments or for fellow programmers.
I find it tedious to fire a debugger and tinker with breakpoints. In the time necessary to do 1 debugger cycle, I think I can do 5 cycles of analysis (add print statements, run, analyse, repeat).
Tight feedback loop.
Development is lots of debugging, so I treat debugging as development. Me, the editor, the code and its test suite.
I don't use a debugger, but I know how to use one and I won't hesitate to use it if my debug routine is not effective in given circumstances. Debugger or not, the test reproducing the bug is a necessary by-product.
Triggered by this tweet.
Further:
- I do not use a debugger (2016/06/21) - an excellent post on an excellent blog with a collection of "no debugger" links
20151224 programmer arrogance
My friend said to me: "to tell you the truth, I've never met a programmer who'd tell me good things about what another programmer built".
He went further: "I had hired a young developer to make a tool for me. It was a continuous struggle to make him accept our needs over the needs he 'envisioned' for the tool. Each of his defeats were punctuated by a warning and an arrogant grin".
20151221 a world split apart
If, as claimed by humanism, man were born only to be happy, he would not be born to die. Since his body is doomed to death, his task on earth evidently must be more spiritual: not a total engrossment in everyday life, not the search for the best ways to obtain material goods and then their carefree consumption. It has to be the fulfillment of a permanent, earnest duty so that one's life journey may become above all an experience of moral growth: to leave life a better human being than one started it.
Aleksandr Solzhenitsyn - A World Split Apart
20151218 stuff and fluff
"Stuff" is tangible. Examples of stuff: documents, business entities, mandates, folder.
"Fluff" is not tangible. If you accept the "what may be touched" definition for tangible, you might accept that fluff is "what does the touching".
Stuff has only two states, "alive" and "dead", but stuff as it traces its arc from birth to death intersects with many fluffs.
Fluff might intersect the stuff's arc or may parallel it for a while and then head away or vanish, or the stuff might vanish before the fluff.
(In passing, here is a link to two releated links: resource lifecycle tuple)
At first, I was tempted to oppose "tangible" to "intangible". Business entities would be "tangible", while business processes would be "intangible".
"Tangible" means "may be touched", ok for business entities, now is "intangible" OK for business processes? I want to express "that does the touching", not "may not be touched". So no "tangible" vs "intangible".